はじめに
Materials Projectの概要とデータの取得方法について解説いたします。
※マテリアルズインフォマティクス関係の内容を他にも投稿していますので、よろしければこちらの一覧から他の投稿も見て頂けますと幸いです。
Materials Projectとは?
Materials Projectは物質材料の第一原理計算結果のデータベースであり、結晶構造、バンド構造、熱力学量、相図、磁気モーメントなどのデータが含まれています。MIT(Massachusetts Institute of Technology)の研究グループが運営を行っており、Li電池材料のデータが特に充実しているとされています。ウェブベースのユーザーインタフェースに加えて、httpベースのAPIも提供されています。登録は必要ですが、利用は無料です。要点をまとめると以下です。
- 約13万個の無機化合物の物性値が含まれているデータベース
- APIとpymatgenを使ってデータ取得が可能
APIとは?
Application Programming Interfaceの略で「アプリケーションをプログラミングするためのインターフェース」という意味です。インターフェイスとは、コンピュータ用語で言うと「何か」と「何か」をつなぐものという意味を持ちます。Materials Projectでは「Materials Projectに含まれるデータ」と「我々のデータ分析環境(プログラムのコード)」をつなぐといった感じでしょうか。
pymatgenとは?
Python Materials Genomicsの略でMaterials Projectのデータの取得や材料解析のためのライブラリです。公式のドキュメントには以下の特徴が挙げられています。
1.Highly flexible classes for the representation of Element, Site, Molecule, Structure objects.
2.Extensive input/output support, including support for VASP (http://cms.mpi.univie.ac.at/vasp/), ABINIT (http://www.abinit.org/), CIF, Gaussian, XYZ, and many other file formats.
3.Powerful analysis tools, including generation of phase diagrams, Pourbaix diagrams, diffusion analyses, reactions, etc.
4.Electronic structure analyses, such as density of states and band structure.
5.Integration with the Materials Project REST API, Crystallography Open Database and other external data sources.
こちらのページからの引用ですが、以下の日本語になるかと思います。
1.材料の中に含まれる元素の種類や位置、構造を、pythonのクラスで柔軟に表現
2.材料研究でよく使われる様々なデータフォーマットに対応
3.相図や電位-pH図を出力したり、化学反応や拡散の解析などに有用な分析ツールが豊富
4.バンド構造や、状態密度などの電子構造解析が可能
5.Materials Project REST APIとの連携が可能
pymatgenについては今後も使っていくことになると思いますので、また勉強してアウトプットしようと思います。
Materials Projectからのデータの取得
こちらのページを参考にMaterials Projectからデータを取得する方法を説明していきます。
環境
- windows10
- conda 4.9.2
- python 3.7.1
- rdkit 2020.03.2.0
- pymatgen 2020.4.29
- pandas 1.1.5
API keyの取得方法
Materials Projectに登録して、APIページに移動すると以下のようにAPI keyが表示されます。
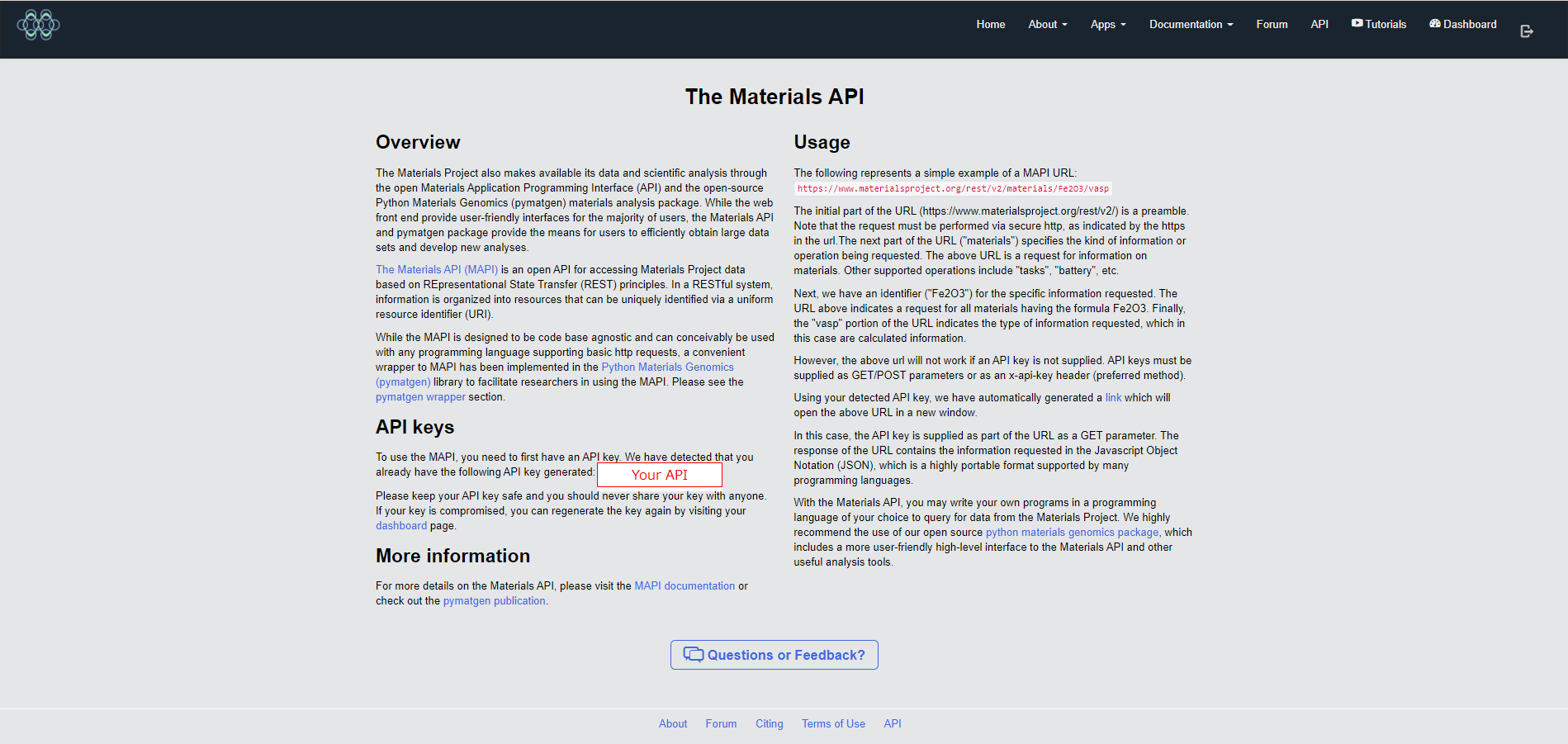
データの取得方法
# ライブラリのインポート
from pymatgen import MPRester
import itertools
import pandas as pd
# Materials Projectに登録して取得したAPIキーを入力
API_KEY = 'Your API'
第2周期の元素の中から二種類を選ぶ組み合わせの化合物のデータを取得していきます。
# 希ガスを除く第2周期までの元素を選択
symbols = ["H", "Li", "Be", "B", "C", "N", "O", "F"]
# 選び出した元素の2個の組合せ(8元素から2つを選ぶので8C2の組合せ)
Comb_2 = itertools.combinations(symbols, 2)
以下のコードでデータを取得し、データフレームに格納します。
with MPRester(API_KEY) as m:
df_COM = pd.DataFrame()
#compoundはlist型
for elements in Comb_2:
compound = m.get_data(elements[0]+'-'+elements[1] , data_type='vasp')
df_com = pd.DataFrame(compound)
df_COM = df_COM.append(df_com)
#結果を保存
df_COM.to_csv('compound_2.csv')
取得したデータはgithubに保存しておきます。保存したデータの大きさを確認します。
df_COM.shape
(329, 28)
参考にしたページではこの実行結果は(302, 28)となっています。恐らくデータベースのデータ数が増えたのだろうと思います。(ですので、今トライしてもこの329という数とは異なるデータ数が得られるかもしれません)
保存したデータフレームを確認します。
df_COM.head()

データフレームの列数は28であり、どのようなデータが取得されたのか確認します。
df_COM.columns
Index(['energy', 'energy_per_atom', 'volume', 'formation_energy_per_atom',
'nsites', 'unit_cell_formula', 'pretty_formula', 'is_hubbard',
'elements', 'nelements', 'e_above_hull', 'hubbards', 'is_compatible',
'spacegroup', 'task_ids', 'band_gap', 'density', 'icsd_id', 'icsd_ids',
'cif', 'total_magnetization', 'material_id', 'oxide_type', 'tags',
'elasticity', 'piezo', 'diel', 'full_formula'],
dtype='object')
バンドギャップや質量など28個のデータを取得できたことが分かります。取得したデータの詳細な解説や取得したデータを利用したモデルの構築などを今後ご紹介していきたいと思います。
まとめ
Materials Projectについて、概要とデータの取得方法について解説いたしました。